01 Introduction and Word Vectors
Language isn’t a formal system,language is glorious chaos
Represent the meaning of a word
1. 语言符号和意义的相互转换
signifier( symbol )<———> signified(idea or thing)= denotational semantics (指称语义)
2. One-hot (离散符号表示)
1 | vocabulary=[0 0 0 0 0 0 0 hotel 0 0 motel 0 0 0 0] //收录所有词汇,维护一个很大的向量 |
feature:
向量正交(没有相似性概念,比较稀疏)
solution:
- 使用WordNet库获取相似度 (不够完整,无法及时更新)
- 学习在向量本身中编码的相似性
3. Distributional semantics (分布式语义)
You shall know a word by the company it keeps (J.R.Firth 1957:11)
现代统计NLP最成功的理念
- 在文本中,单词$w$附近的一组单词(一定size的窗口)称为上下文(context words )
- 用$w$的context words来构建$w$的表示

即一个单词的语义由他所处的语境(上下文)来表示,基于统计
Word2vec
- 构建单词的密集向量(word vectors OR word embedding)(基于Distributional semantics),解决One-hot表示稀疏的问题。
- 使其与出现在相似上下文中的单词向量相似,因为处于相似语境下的单词具有相似语义
Word2vec(Mikolov et al. 2013)是一个学习单词向量的 框架
- 固定词汇表中的每个单词都由一个词向量表示
- 文本中的每个位置 t,其中有一个中心词 c 和固定窗口的上下文单词 o
- 使用 c 和 o 的 词向量的相似性 来计算给定 c 的 o 的 概率 (反之亦然)
- 不断调整词向量 来最大化这个概率
下图为窗口大小 j=2 时的 $P(w_{t+j} | wt)$ 计算过程,center word分别为 intointo 和 banking
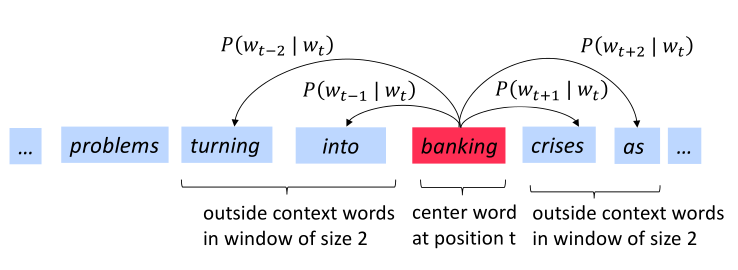
Word2vec objective function
对于每个位置t=1 , … , T,在size为m的窗口预测上下文
相似度度量
$\theta$是需要优化的变量
损失函数(loss function)
- 使用log对$L(\theta)$取对数,方便将连乘转换为求和 $log\prod_{i}x_i=\sum_{i}logx_i$
- 负号,将极大化似然转换为极小化损失函数,(最小化损失函数$\Leftrightarrow$最大化预测精度),梯度下降求解。
关于$P(w_{t+j} | w_{t})$
$v_w$当 $w$ 是中心词时
$u_w$当$w$是上下文时
对于中心词$c$和上下文词$o$
- 具体含义:具有相似上下文的单词,具有相似向量
- 分母,对词汇表标准化,给出概率分布
- $u_o和v_c$点乘,表示相似度大小,点积越大概率越大
- 取幂保持结果为正