Python 进程池对简单多参数循环的并行加速
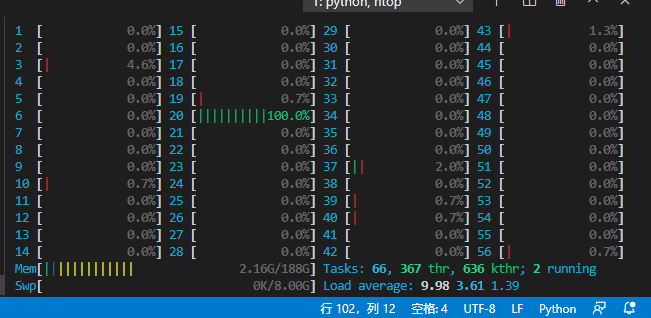
在对一个集成学习的项目做参数调整的时候,发现循环内部操作比较耗时,并且集成的模型较多。整体的自动调参很耗时,考虑到循环内部不存在数据依赖,所以使用python进程池进行加速。服务器有56个计算核心,最终加速比大概50多倍。
调参人狂喜。
multiprocessor库
主要是使用了python的multiprocessing 库,一个支持使用与 threading 模块类似的 API 来产生进程的包。 multiprocessing 包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了 全局解释器锁。 因此,multiprocessing 模块允许程序员充分利用给定机器上的多个处理器。 它在 Unix 和 Windows 上均可运行。
可以使用Process动态成生多个进程,手动的去限制进程数量,比较复杂
但是我直接使用提供的Pool进程池,可以提供指定数量的进程供用户使用,当有新请求提交到pool中时,如果进程池还没有满,就会创建一个新的j进程用来执行该请求。
实例
1 | # Python库函数 |
结果对比
由于我的代码涉及到文件I/O,所以有些操作比较复杂,函数内部耗时比较长。
由于我们服务器有56个逻辑核心,开辟56个进程,加速比大概50多倍
56核
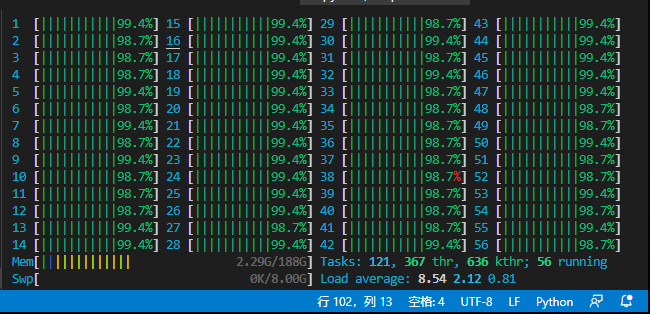
单核